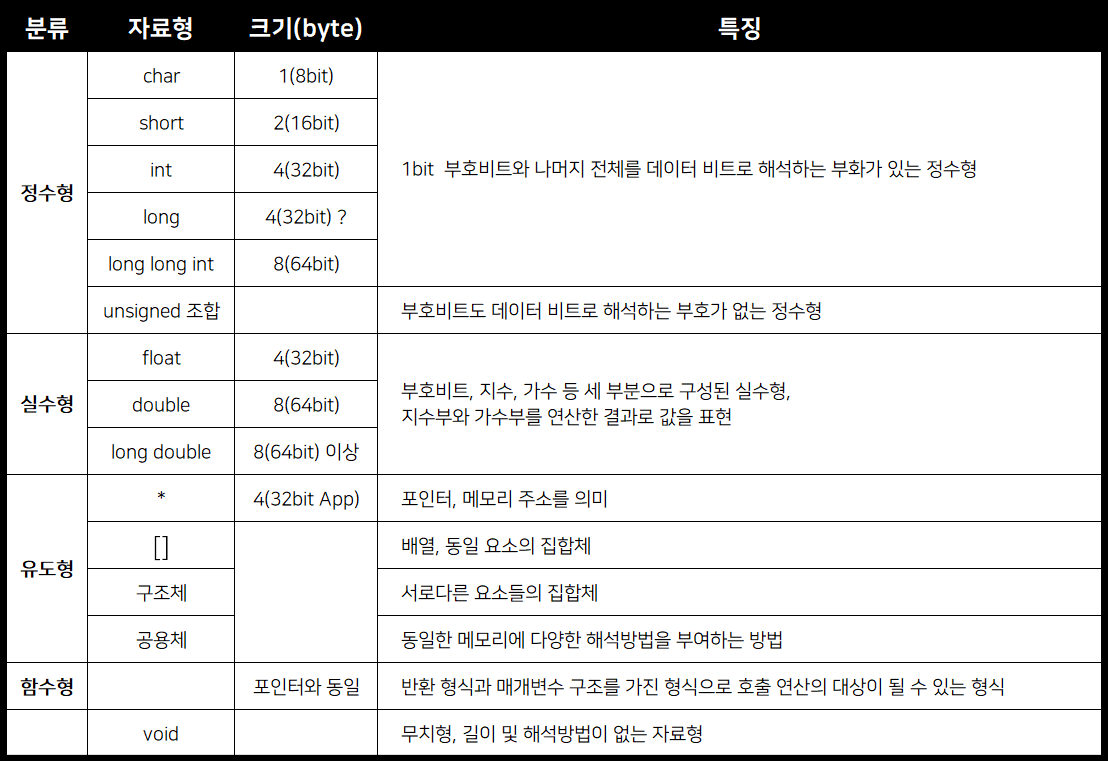
[C] TIL 3. 자료형의 종류
in PROGRAMING STUDY on C
- 실수 10.0과 10.0f의 차이를 기술해라.
- 실수형 세가지와 최소범위를 기술해라.
char형으로 선언한 변수가 3개가 있다. 각각 1, ‘1’, “1”을 넣게 되면 어떻게 되는가?
boostcourse의 모두를 위한 컴퓨터 과학 (CS50 2019) 강의를 듣고 정리한 필기입니다. 😀
컴퓨터는 서로 다른 종류의 데이터를 인식하고 사용할 수 있는 방법이 필요하다. C는 이 일을 하기 위해서는 변수와 상수를 제외하고도 더 세세하게 구분해야 한다. 만약 데이터가 상수라면, 컴파일러는 표시된 모양 그대로의 데이터를 인식한다. (42는 정수고 42.1은 부동소수점으로 인식한다.) 하지만 변수는 선언을 통해 무슨 자료형인지 알려야 한다.
1. 정수형

정수(integer)는 소수부가 없는 수이다. C언어에서 정수로 선언된 변수에는 수소점이 있는 수는 담을 수 없다. 그리고 C는 다양한 정수형을 제고한다. 그 이유는 프로그래머가 용도에 따라 적당한 것을 선택하여 사용할 수 있게 하기 위함이다. 그리고 정수형은 값의 범위와 음수를 사용하느냐에 따라 달라진다.
1.1 int형
int 형은 양수, 음수, 0이 될 수 있고, 허용하는 값의 범위는 컴퓨터 시스템에 따른다. 즉, 부호가 있는 정수(singed integer)라고 할 수 있다. 그리고 컴퓨터의 1 word로 저장된다. 따라서, 16bit word를 사용하는 컴퓨터에서는 int는 16bit 즉, 2byte가 된다. 32bit에서는 32bit 즉, 4byte가 된다. 만약 우리의 퍼스널 컴퓨터가 64bit word를 사용한다면 int는 64bit 즉, 8byte가 될 것이다.
8진수와 16진수
일반적으로 C는 정수형 상수로 10진수를 가정한다. 그러나 8과 16은 2의 거듭제곱이지만 10은 아니라는 이유로 프로그래머들은 8진수와 16진수를 좋아한다. 8진수와 16진수 체계가 컴퓨터와 관련된 값을 표현하는데 더 편리하기 도하다.
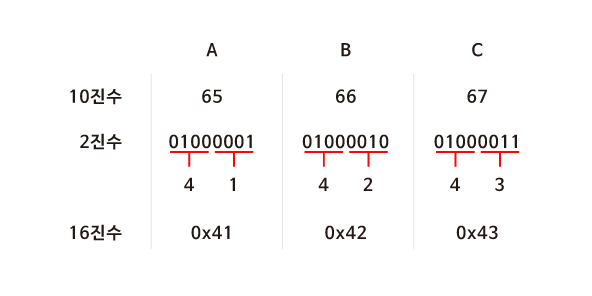
16bit 컴퓨터에서 자주 등장하는 수인 65536은 16진수로는 10000이다. 그리고 16진수에서 하나의 숫자는 정확히 4bit에 해당한다. 예를 들어 16진수 숫자 4는 0100이고, 16진수의 숫자 3은 0011이다. 그리고 16진수의 42는 0100 0011에 해당한다. 그리고 이것은 10진수에서는 67에 해당한다. 이것만 보아도 알 수 있듯이 16진수는 10진수보다 2진수 체계 사이를 전환하는 것을 쉽게 만든다. 그런데 프로그램을 사용했을 때 42라는 글자만 덜렁 나온다면 이 42가 10진수인지, 8진수인지, 16진수인지를 구분할 수 없을 것이다. 그래서 C는 구분을 위해 특별한 접두사(prefix)를 사용한다. 16진수는 접두사로 0x 또는 0X(zero-ex)를 사용한다. (16진수의 42는 0x42로 표현된다.) 8진수는 0(zero)을 접두사로 사용한다. (8진수의 42는 042로 표시된다.)
하지만 이러한 표시는 순전히 사용자를 위한 것이다. 컴퓨터 내부에서는 67, 042, 0x2 어느 것을 사용하더라도 2진수 코드로 동일하게 저장된다.
1.2 sort, long, long long 형
long 형과 short형은 int형보다 더 많거나 혹은 더 적은 메모리를 사용할 수도 있다. 한다는 확정이 아닌 할 수도 있다는 가능성으로 문장은 마무리된다. 이유는 C언어가 long형과 short 형을 int와 대비하여 길거나 짧다는 것만 보장했기 때문이다. 정확한 비트 없이 이렇게만 정의한 것은 데이터형을 기계에 맞추기 위함이다. Windows 3을 사용하던 시절 int형과 short형 둘 다 16bit이었고, long은 32bit였다. 그 뒤로 발전을 하면서 short형은 16bit, int형과 long 형은 32bit가 되었다. int형에서 설명했듯이 int는 컴퓨터의 1 word에 따라 정의되기 때문이다. 32bit는 20억 이상의 큰 정수를 나타낼 수 있다. 하지만, 발전을 거듭하면서 프로세스 대부분은 64bit를 쓰고 있어서 64bit 정수형이 필요했고, 이게 long long형이 태어난 동기이다. 때문에, long long형은 62bit, long형은 32bit, short형은 16bit, int 형은 시스템의 고유 word에 따라 16bit 혹은 64bit가 된다.
1.3 char형
1.3.1 표준 ASCII 코드
char 형은 글자와 구두점 같은 문자들을 저장하는 데 사용된다. 그러나 컴퓨터는 오로지 숫자만 표현할 수 있음으로 char형은 정수형으로 분류된다. 이때, 컴퓨터에 문자를 처리하기 위해 숫자를 문자로 규정하도록 하였다. 이를 부호체계라고 한다.
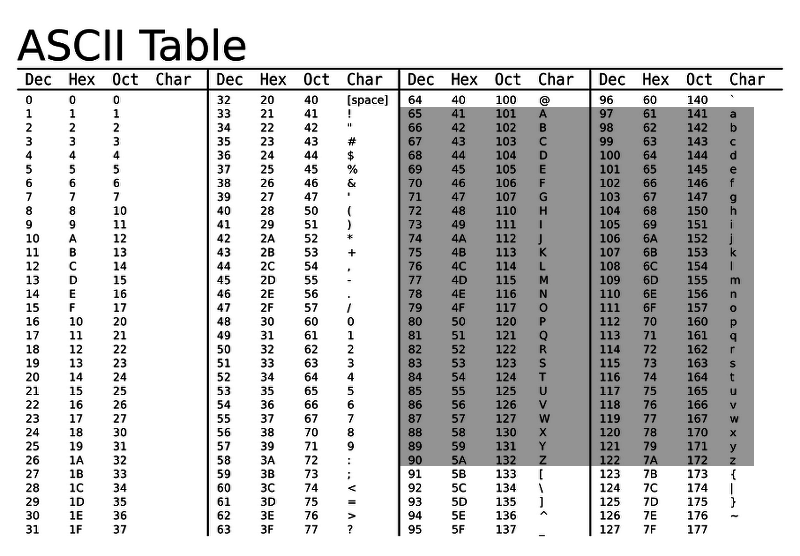
위는 표준 ASCII 코드라는 것이며, 0부 127까지의 정수들에 각각 문자를 대입하고 있다. char형으로 선언된 변수에 65가 담겨 있으면, 출력할 때 65가 아니라 대문자 A를 출력한다. 이 방법은 유요하지만, 유효하지만 좋은 방법은 아니다. 반대로 우리가 char형으로 선언한 변수에 대문자 A를 넣으면 컴퓨터에는 65로 저장된다. (2진수로 저장될 테니 실제 기계어를 열어보면 0110 0101이 될 것이다.)
1.3.2 char형 배열과 널문자.
C언어를 배울 때 가장 착각하기 쉬운 것 중 하나가 문자배열(character string)이다. 배열이란 동일한 데이터형을 가진 여러 데이터 원소들이 메모리 순서대로 나열되어 있는 연속물이다. 하지만, 흔히들 문자 배열을 문자열이라고 부른다. 즉, 그만큼 그 본질이 배열이라는 것을 모르고, 다른 자료형처럼 인스턴스가 한 개라고 착각한다는 것이다. 개다가 길이도 우리가 설정하기 나름이라 생각해야할 것이 많다.
“all of time and space, everything that ever happened or ever will”
위와 같은 문장이 있다고치자.
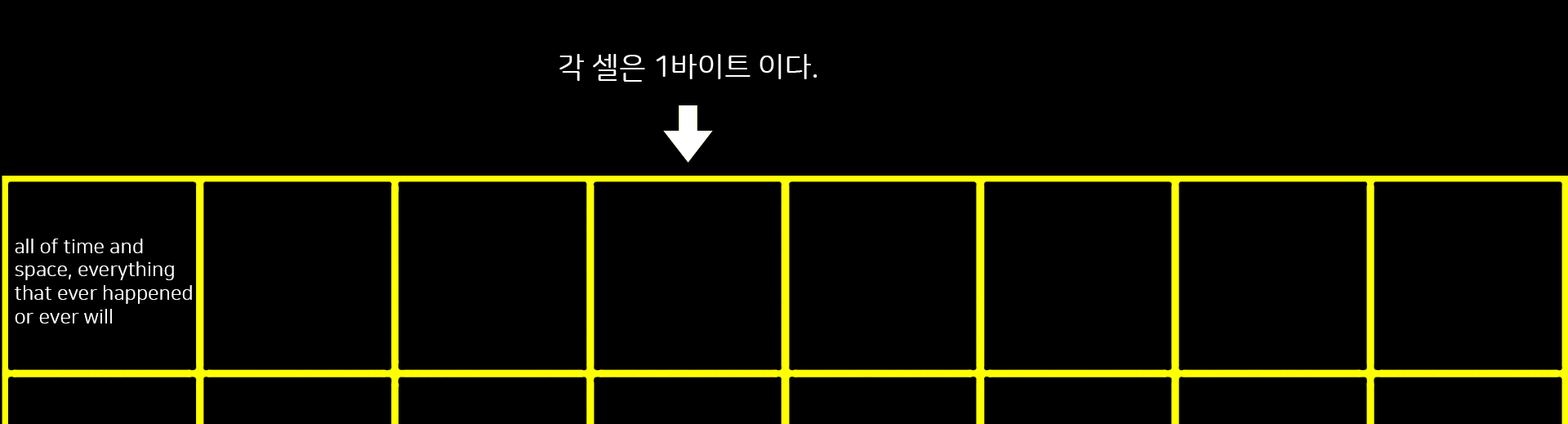
위와 같은 형태가 한 개의 인스턴스인 것이다. 하지만, 많은 양의 문자는 저런식으로 1byte에 다 들어가지 않는다.

char은 긴 문장을 위 그림처럼 연속적인 메모리 셀들에, 셀 당 한 문자씩 저장된다. 이 문자배열의 마지막 위치에 \0가 있는 것은 널 문자(null character 혹은 널 종단 문자)로써, 문자열의 끝을 나타낸다. 널 종단 문자는 숫자 0이 아니기 때문에 표준 ASCII 코드에 의해서 0이 출력되지 않는다. C에서 모든 문자열은 그 끝을 알리는 역할인 널 종단문자와 함게 저장한다. 그리고 널 종단 문자에 의해서 저장할 문자들의 수보다 셀 수가 최소한 하나 더 많아야한다는 뜻이기도 한다. 즉, 총 65글자로 되어있는 문자배열을 저장하는데 퐁 66byte가 필요하다는 것을 의미한다.
char DWScript[66];
DWScript 뒤에 있는 각괄호([])에 의해서 DWScript를 배열로 인식한다. 각 괄호 안에 있는 숫자는 해당 배열의 원소 수를 나타낸다. 앞에 있는 char은 해당 변수가 자료형이라고 선언한 것이다.
1.3.2 문자 상수와 초기화
int main(void)
{
char str = '65';
int num = 65;
str = 65;
return 0;
}
참고로 위처럼 작은따옴표로 묶여있는 숫자와 그렇지 않은 숫자는 엄연히 다르다. 작은따옴표로 묶여있는 것은 문자형이고, 작은따옴표 없는 것은 숫자에 해당한다. char형으로 선언된 변수에 따옴표가 없는 수를 입력하면 숫자가 아닌 65에 해당하는 문자가 저장된다. 그래서 만약 str을 출력하기 되면 65이 아니라, A가 출력될 것이다.
int main(void)
{
char str1; // char형 변수 선언.
str1 = 'A'; // A를 문자이라고 생각함.
str1 = A; // A를 변수라고 생각함.
str1 = 'A'; // "A"를 문자열이라고 생각함.
return 0;
}
작은따옴표 사이에 있는 하나의 글자가 문자 상수(character constant)이다. 컴파일러가 ‘A’를 만나면, 이것을 해당하는 코드 값으로 변환한다. 위 코드를 보면 작은따옴표를 생략한 경우와 작은따옴표 대신 큰따옴표를 사용했을 경우가 있다. 작은따옴표를 생략할 경우, 컴파일러는 A를 변수 이름이라고 생각한다. 작은따옴표 대신 큰따옴표는 A를 문자열(string)이라고 생각한다. 문자 상수와 문자열은 다른 것이다.
1.3.3 이스케이프 시퀸스(escape sequence)
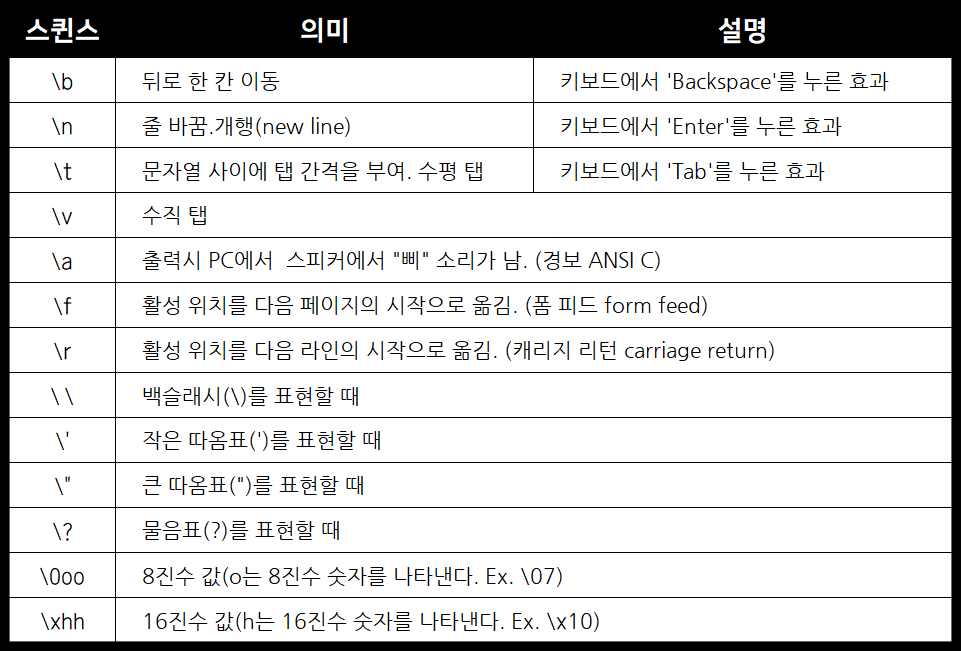
작은 따옴표는 문자, 숫자, 구두점들을 모두 붙일 수 있다. 그리고 표준 ASCII 코드표를 살펴보면 한 자 역행, 개행, 경보, 등 문자가 아닌 행동 또한 존재한다. 이것을 표현하고 저장하기 위해서는 두 가지 방법이 있다. 첫 번째 방법은 ASCII 코드 값을 직접 사용하는 것이고, 두 번째 방법은 위 표에 나오는 이스케이프 시퀀스 (escape sequence)를 사용하는 것이다.
1.4 부호비트와 최소 범위
1.4.1 부호비트
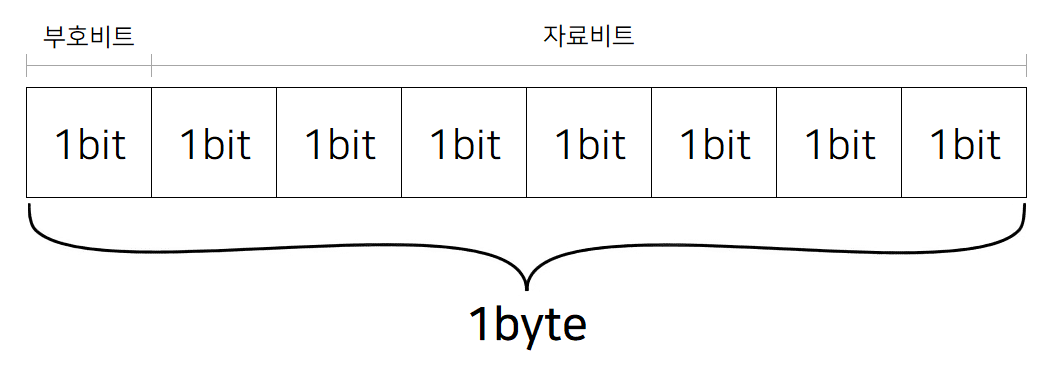
표에 있는 부호 비트(sign bit)는 무엇을 뜻할까? 8bit는 곧 1byte이다. C 언어의 자료형에서 부호가 있는 정수의 경우 가장 왼쪽 1bit는 부호 비트로 사용되며, 나머지 7bit는 데이터 비트(자료 비트)로 사용된다. 이 부호 비트가 0이면 자료 비트의 정보는 양수가 되는 것이고, 1이면 음수가 된다.
1.4.2 최소범위
2진수는 0과 1로 이루어져 있으며, 이것을 가지고 데이터를 표현해야 한다. 여기에 부호 비트를 제외하면 우리에게는 7bit 밖에 없다. 따라서, 1byte로 표현할 수 있는 경우의 수는 128(2의 7승)가지이다. 따라서 8bit 단위인char형은 양수는 0부터 127 (128개)이며, 음수는 -1부터 -128까지이다.
C언어는 각각의 데이터형에 대해 최소 허용 크기를 지정하는 가이드라인이 있다. short형과 int 형은 둘 다 -32768에서 32767까지이며, 이것은 16bit 단위에 해당한다. long형은 -2,147,483,648에서 2,147,483,647까지이며, 이것은 32bit 단위에 해당한다. long long형은 -9,223,372,036,854,775,808에서 9,223,372,036,854,775,807까지가 최소 범위이며, 64bit에 해당한다.
unsigned 형은 음수가 아닌 값들만 가지는 변수에 사용한다. 이 데이터 형은 부호 비트가 필요 없기 때문에 저장할 수 있는 범위가 변한다. 따라서 1byte 즉, 8bit를 전부 사용하게 된다. 1byte로 표현할 수 있는 경우의 수는 226(2의 8승)가지이다. 8bit unsigned char형은 0부터 225(226개)가 최소 범위가 된다. 16bit unsigned sort와 unsigned int형은 -32768에서 32767까지 범위 대신 0에서 65525까지의 범위를 허용한다. 32bit unsigned long은 0에서 4,294,967, 295까지이다. 64bit unsigned lon long형은 에서 18,446,744,073,709,551,615까지이다.
위 정보를 요약하면 아래와 같다.

이러한 unsigned형은 음수가 필요 없고, signed보다 더 큰 범위의 양수를 가질 수 있기 때문에 수를 셀 때 사용하는 것이 자연스럽다.
2. 실수형

실수 자효형은 소수점 이하의 정보까지 표현할 수 있는 자료형을 말하며 다른 말로는 부동 소수점 수(floating-porint number)이라고도 한다. 부동 소수점이 의미하는 것은 100.0이라는 실수에 10을 곱하게 되면 소수점의 위치가 다른 자리로 변경될 수 있음을 의미한다. 이러한 부동소수점 수를 C에서는 float형, double형, long double 형이라 부른다.
2.1 최소범위

C 표준은 float형이 최소한 6 자릿수 유효숫자를 나타내야 하고, 1.17 × 10^-38부터 3.4 × 10^38까지 허용해야 한다고 규정했다. 최소 6 자릿수 유효숫자란, 예를 들어 3.333333333…와 같은 수를 3.333333처럼 소수점 6자리 수까지만 나타내야 한다는 것이다. 1.17 × 10^-38부터 3.4 × 10^38란 범위는 태양의 질량이나 양성자의 전하량 또는 국가 채무 같은 수를 다루고 싶다면 float 형이 편하다는 것이다. 이러한 부동소수점 수는 32bit로 저장하며, 8bit는 지수부(exponent)의 크기의 부호에 해당하고, 나머지 24bit가 가부수(mantissa 혹은 significand)의 크기의 부호에 사용된다.
배정도(double precision) 부동소수점형으로는 double형을 제공한다. 이 double형의 최소 범위는 2.22 * 10^-308 ~ 1.79 * 10^308이며, 최소한 15자리 수 유효숫자를 나타내야 한다. 일반적으로 double 형은 32bit가 아니라 64bit를 사용한다.
마지막으로 long double형은 double형 보다 높은 정밀도를 제공한다.
2.2 부동소수점형 상수 (리터럴)
-1.56E+12
2.87e-3
부동소수점 상수의 기본은 e 또는 E일 것이다. 그리고 그 뒤에 10의 거듭제곱을 나타내는 부호 있는 지수부가 나올 것이다. C에서 부동소수점 상수를 적을 때는 선택의 폭이 넓다.
- 플러스 기호(+)를 생략해도 된다. 소수점이 없어도 되고, 지수부가 없어도 된다. 하지만 이 둘이 동시에 없는 건 허용되지 않는다.
- 또, 소수점 아래가 없어도 되고, 소수점 위가 없어도 괜찮지만, 이 둘이 동시에 없는 건 허용하지 않는다.
그리고 마지막으로 부동소수점형 상수 안에 스페이스를 넣는 것은 허용되지 않는다.
#include <stdio.h>
int main (void)
{
printf("%f\n", 123.000); // => 123.000000
printf("%f\n", 123.0 + 20.0); // => 143.000000
123.0; // bouble;
123.0F; // float;
printf("%f\n", 123.45); // => 123.450000
printf("%f\n", 123.45f); // => 123.449999
return 0;
}
자료형 선언 없이 부동소수점을 사용하면 자동을 double형으로 저장된다. 컴파일러는 부동소수점형 상수들이 배정도라고 생각하기 때문이다. 하지만, 접미사로 f나 F를 사용하면 double 형이 아닌, float형으로 취급한다. 반면, 접미사로 l과 L을 사용하면, 데이터형을 long double형으로 취급한다. (하지만 소문자 L을 사용하면 1과 혼동할 수 있으니, 대문자로 쓰는 것이 좋다.)
0xa.1fp10
C99에서는 위와 같은 형태도 허용한다. 16진수 접두사인 0x, 16진수 숫자, (e 나 E 대신에) p 또는 P 허용, 10의 거듭제곱 대신 2 거듭제곱인 지수부를 사용한 숫자이다. 여기서 a는 10, .1f는 1/16 + 15/256를 나타낸다. p10은 2^10(1024)이다. 이 값은 10진수로 하면 10346.0이 된다.
2.3 근사값처리

이러한 부동소수점 형이라는 것은 근사값 처리 때문에 근본적인 오차를 가지고 있다.
float형은 6자리까지 유효하다. 그럼 7번째 자리는 유효하지 않다는 말인데, 이는 정확성이 떨어진다는 말과도 같다. 그래서 실수형을 선언할 때는 float형 보다 double형으로 써야 한다. 단, 15자리 수가 넘어갈 것 같으면 역시 double 형보다는 long double 형이 낫다.
#include <stdio.h>
int main(void)
{
printf("%f\n", 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + 0.5f + ... + 0.5f);
}
위와 같은 코드를 어느 단계까지 하게 되면 값이 깨지기 시작한다.
#include <stdio.h>
int main(void)
{
printf("%f\n", 1247483648.0f); // 1247483648.000000
printf("%f\n", 1247483648.0f-20); // 1247483648.000000
printf("%f\n", 1247483648.0f-40); // 1247483648.000000
printf("%f\n", 1247483648.0f-60); // 1247483648.000000
printf("%f\n", 1247483648.0f-64); // 1247483648.000000
}
float형은 6자리까지 유효해서뿐 아니라, 32bit 형식이기 때문이기도 하다. 위 코드에서 출력한 1247483648이란 숫자는 2³¹의 값이다. 20, 40, 60, 64.. 등등 무엇을 빼도 출력은 1247483648이 된다. 정수 수준에서 보면 무려 64라 만큼의 오차가 나는 데도 인식을 하지 않는 것이다. 이렇듯, float 형은 10억 단위 이상으로 넘어가면 그때부터 근사값에 의한 오류가 난다.
#include <stdio.h>
int main(void)
{
printf("%f\n", 1247483648.0f); // 1247483648.000000
printf("%f\n", 1247483648.0f-65); // 1247483520.000000
}
65를 빼줬을 경우, 원래 값에서 차감은 되지만, 그 값이 맞지 않는다. 어찌 되었건 결과값에 변동은 있었다. 왜일까?
1247483648의 끝에서 세자리(648)와 65를 빼면, 128이 된다. float형은 n과 n+1 사이의 근삿값 인정 폭이 128인 것이다. 부동소수점은 근삿값을 쓰다 보니 이런 명백한 오차가 생길 수밖에 없다. 그렇기 때문에 flaot을 사용하지 말라는 것이다. 일례로 1247483648.0f에서 f를 빼고 1247483648.0을 쓰게 되면 boudle형으로 인식하여 제대로 된 값이 나온다.
