[CS] TIL 21. 해시 테이블, 트라이, 스택, 큐, 딕셔너리
- 해시 함수는 어떻게 만들 수 있을까?
- 트라이가 해시 테이블에 비해 가지는 장점과 단점은 무엇일까?
- 여태까지 배운 개념들을 기반으로 해서 나만의 새로운 자료 구조를 만들어 볼 수 있을까?
boostcourse의 모두를 위한 컴퓨터 과학 (CS50 2019) 강의를 듣고 정리한 필기입니다. 😀
1. 해시 테이블

위의 그림을 보면 맨 위에 있는 O(n²) 너무 느리고 반대로 맨 아래에 있는 O(1)은 아주 빠른다. 또한, O(1)는 항상 일정하다. 연결리스트의 시간복잡도는 O(n)이었고, 이진 탐색 트리는 O(log n)이었다. 밑으로 내려갈 수록 빠르기 때문에 최상의 자료구조는 시간복잡도가 O(1)인 자료구조일 것이다. 원하는 값을 찾을 때 단 한번의 단계만 할 수 있고, 무언가 찾을 때도 한 번에 찾을 수 있다면 좋을 것이다. 이렇게 원하는 값을 바로 접근하게 하는 것이 해시테이블이다. 하지만 그것을 구현하는 방법은 명확하지 않고, 약간의 전문 지식도 필요하다.
쉬운 예로 철자 검색 프로그램이 있다. 철자 검색 프로그램이 철자가 맞는지 틀렸는지 확인할 때마다 아주 큰 사전을 검색한다면 시간복잡도는 O(n)이나 O(log n)이 될 것이다. 한 파일을 모두 검사하는 데 아주 많은 시간이 걸린 다는 것이다. 하지만 해시테이블을 사용하면 훨씬 더 빠르게 할 수 있을 것이다.
1.1 해시 테이블

위 그림을 보자, 해시테이블에서는 편의상 세로로 그리지만, 가로로 그렸던 배열과 같은 것이다.
예를 들어 우리는 큰 행사를 앞두고 있고 미리 이름표를 만들어둬야 하는 상황이다. 우리의 목표는 해시테이블을 이용해서 사람들이 이름표를 효율적이게 가져가도록 하는 것이다. 이름표를 한 바구니에 다 넣는다면 행사 참여자들은 참가자 모두 한 줄로 서서 모든 이름표를 뒤져가며 찾아야 한다. 설령 A부터 Z까지 알파벳 순서대로 정리되었다고 해도 말이다.
하지만 A~Z까지의 라벨이 달린 몇 개의 바구니를 나누어 담는 다면 훨씬 더 빨리 찾을 수 있다. 각자의 이름표를 찾기 위해 자신의 바구니로 가서 자신의 이름을 찾아낼 수 있기 때문이다. 특히 그 철자로 시작하는 이름이 자기 뿐이라면 바로 찾을 수도 있을 것이다.

해시테이블에서는 단어나 이름같은 입력값이 들어오면 그 단어에 포함된 문자를 보고 어디에 그 이름을 넣을 결정하는 방식에 흔하게 사용된다. 위의 배열은 0부터 25까지, 총 26칸으로 되어있고, 이 배열에는 A부터 Z 순으로 순서가 정해져있다.(하지만 근본적으로는 26개 짜리의 배열이다.)
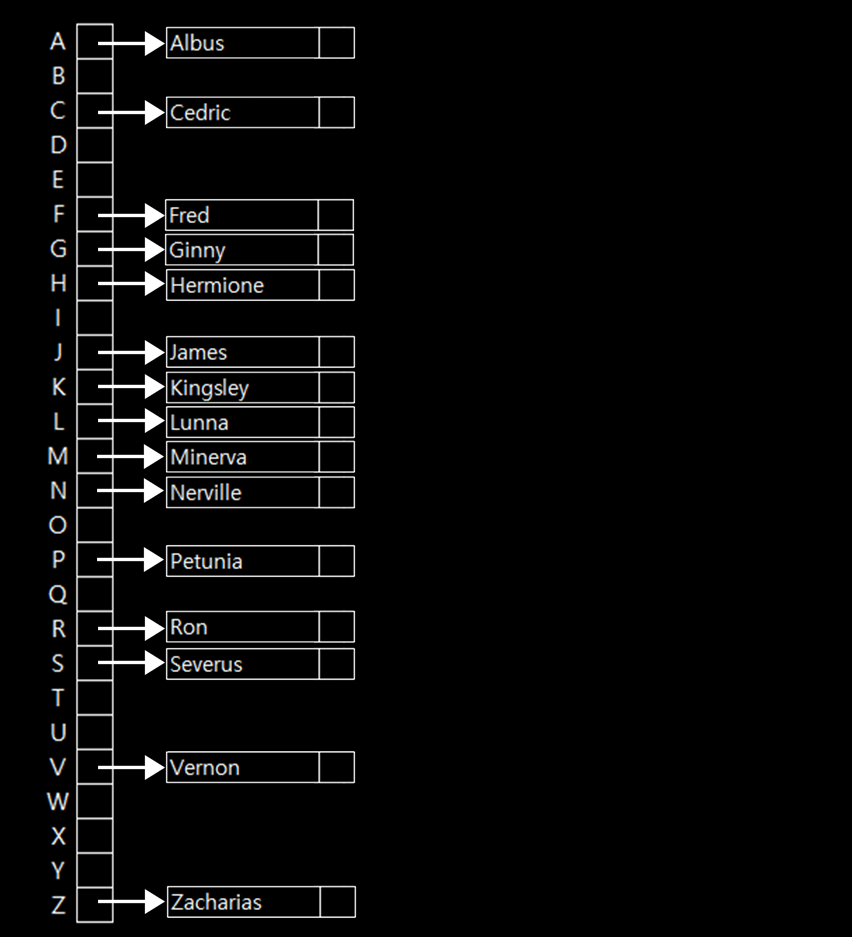
Albus라는 이름표는 0번의 포인터가 가리키게 되고, 반면 Zacharias의 이름표는 마지막 배열의 포인터가 가리킬 것이다. Hermione는 H로 시작하니까 7번째 배열의 포인터가, Ginny는 6에, Ron은 17… 이렇게 알파벳 숫자대로 넣어두면 참자가자들이 이름표를 다 뒤질 필요가 없어진다.
이름표를 찾는 속도는 빨라졌지만 여기에는 문제가 있다. 지금까지는 각 알파벳당 한 개의 이름을 넣었지만, 알파벳당 복수의 이름표를 넣으면 어떻게 하면 될까? 만약 배열을 하나만 사용하면 Harry라는 인물은 자신의 이름을 찾을 수 없을 것이다. 왜냐하면, H라는 배열에는 Hermione의 이름표가 이미 존재하기 때문이다. 해시테이블에서는 한 배열에 포인터는 2개 이상이 존재할 수는 없다. 컴퓨터 공학에서는 충돌이라고 부르며, 어떤 값을 넣으려고 하는데 이미 값이 들어있는 경우, 어떤 방법으로든 이것을 해결해야한다.
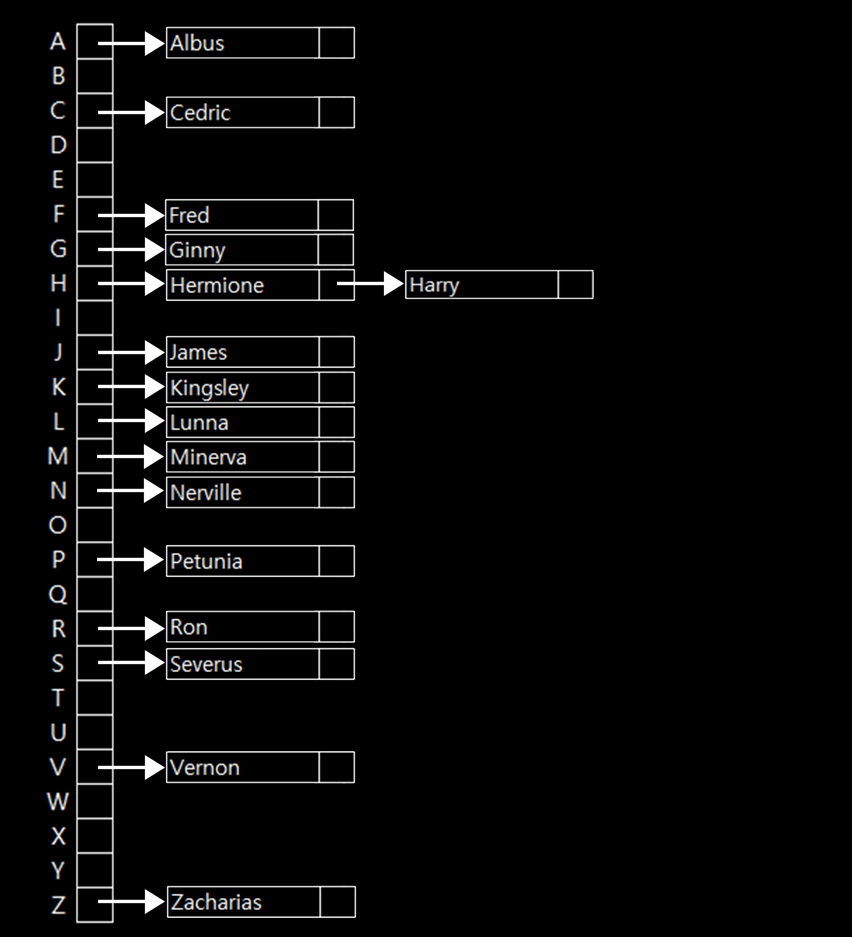
해시테이블은 이것을 해결하기 위해 가로 방향으로 연결리스트를 만들 수 있다. 위 그림처럼 Hermione와 Harry의 이름표를 연결해서 두 단계만에 Hermione와 Harry 라는 이름표를 모두 찾을 수 있게 된다. 하지만 이렇게 되면 일표를 찾는데에 걸리는 시간이 O(n)은 아니게될 것이다.
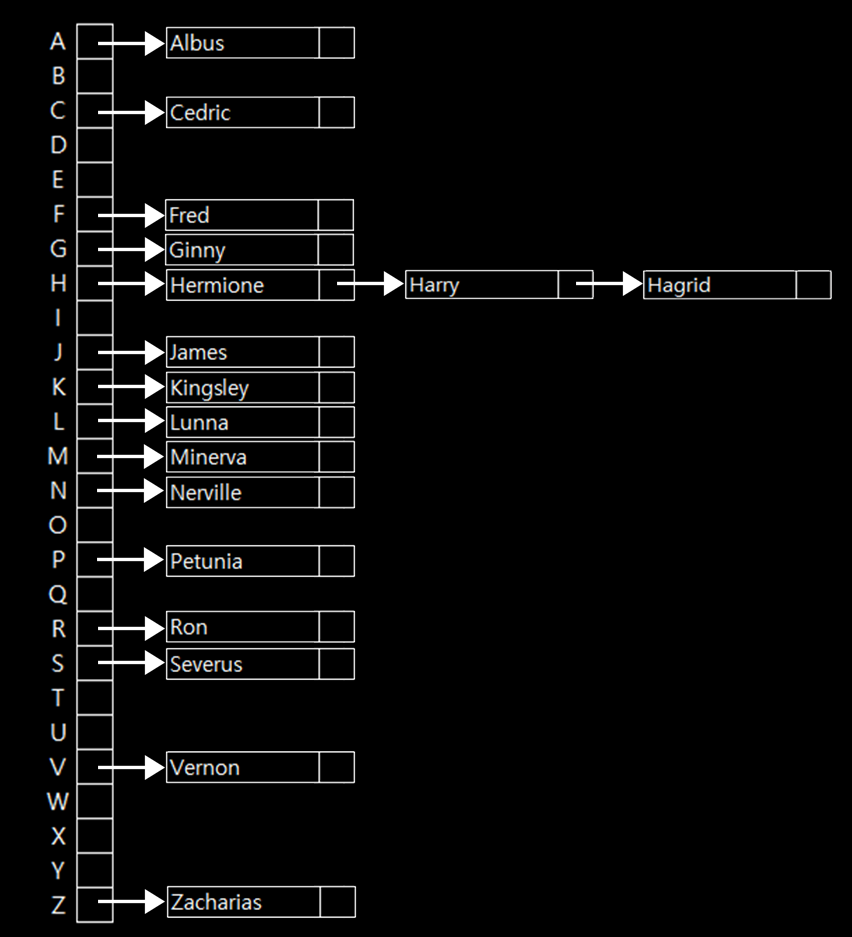
Hagrid도 7번째 배열에 넣으려고하면 위와 같은 형태가 될 것이다. 때문에 Hagrid는 7번째 배열의 끝에 있는 리스트 Harry와 연결하면 된다. 이제 7번째 배열은 크기가 3인 연결리스트가 됐다는 것이다.

이제 나머지 이름을 넣어보자. Sirius는 Severus가 이미 존재하는 18번째에 넣어야 하기 때문에 Sirius와 Severus 와 연결하고, Remus는 Ron과, George는 6번째 배열에 있는 Ginny와 연결하면 된다. Lily까지 Lunna와 연결하면 위 그림과같은 형태가 된다.

여기에 Lusius까지 더 해준다면 위 그림이 완성될 것이다. 이 구조가 바로 해시테이블이다.
1.2 해시 함수
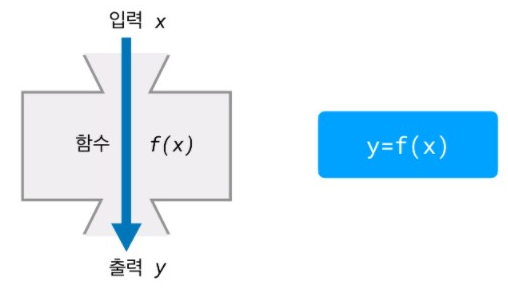
어떤 바구니에 담을지가 결정되는 과정은 ‘해시 함수’라는 맞춤형 함수를 통해서 이루어진다. 해시 함수는 지금까지 본 다른 함수, 다른 프로그램들과도 똑같이 입력받을 받아서 출력값을 내보낸다.(위는 TIL2에서 보았던 그림이다.) 즉, 오늘 배우는 해시 함수는 어떤 함수이자 과정이자 알고리즘이다.

해시 함수는 Albus이 입력값이 되면 0이 반환되어서 0번째 배열(A에 해당하는 배열)에 담기게 된다. Zacharias는 첫 번째 글자가 Z이기 때문에 해시 함수의 입력값이 되면 25이라는 출력값이 나온다.
하지만 여기에는 첫 글자가 같은 이름은 다수라는 문제가 있다. 컴퓨터 과학자들과 소프트웨어 엔지니어들은 종종 극단적인 상황까지 고려한다. 아주 만약에 H나 L로 시작하는 이름이 아주 많거나 참가자 모두가 H나 L로 시작한다면 해시테이블을 사용하더라도 바보 같은 형태가 될 것이다. 해시테이블은 굉장히 효율적인지 몰라도 이런 경우를 생각하면 최악의 경우 삽입과 검색 모두 O(n)의 시간이 걸리게 된다. 운이 정말 나쁘다면 찾아가지 모두 H로 시작하는 이름일 수도 있다.

이 문제를 해결하기 위해서는 몇 가지 방법이 있을 것이다. 첫 번째는 첫 번째 글자뿐 아니라, 두 번째 글자까지 살펴보는 것이다. 그렇게 한다면 많은 사람이 같은 바구니에 배정되지 않을 것이다. 좀 더 쉬운 이해를 위해서 첫 글자가 H인 것만 살펴보자.
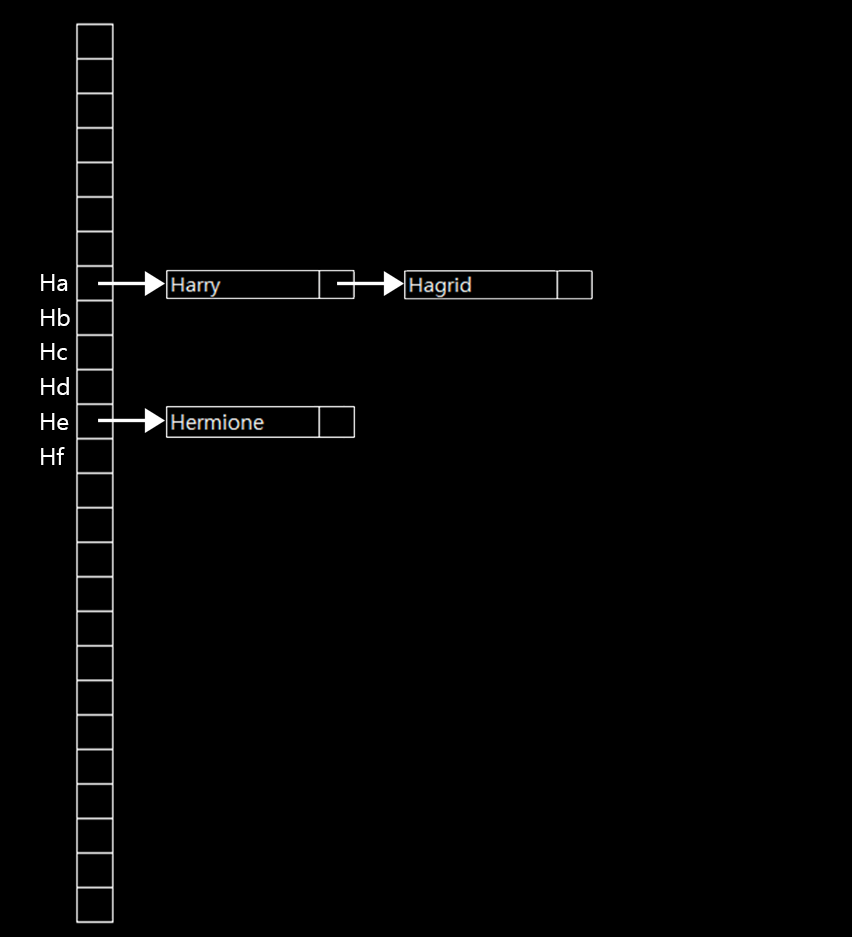
H에는 Hermione, Harry, Hagrid가 있다. 그리고 Ha, Hb, Hc, Hd, He, Hf…. Hz까지에 해당하는 배열이 있을 것이다. 이렇게 한다면 더 많은 바구니가 필요할 것이다.(아마 26*26해서 총 676개의 바구니가 필요할 것이다.)공간은 더 많이 필요하지만, 충돌할 확률과 H 칸만이 길어질 확률은 낮아질 것이다.
두 번째 글자까지 살펴본다면, 단순히 H라는 배열에 연결되어있던 이름 세 개는 위 그림처럼 배분될 것이다. 다만 여전히 Harry와 Hagrid는 Ha에 해당하는 배열에 같이 있다. 이 방법 또한 최고의 방법은 아니라는 것이다.
이것을 해결하기 위해서 세 번째 글자까지 확인한다면 필요한 배열이 너무 많아지기 때문에 실행시간은 여전히 O(n)에 해당한다. Hermione, Harry, Hagrid 모두 다른 배열에 담겨있어서 한 번에 찾을 수 있겠지만, 이건 어디까지나 H로 시작하는 이름이 그렇게 많지 않을 가정했을 때의 이야기이다. 비슷한 철자를 가진 이름이 다수가 들어온다면 또 충돌이 생길 것이다. 그럴 때마다 n번째, n+1번째…. n+n번째의 글자까지 확인하는 프로그램을 만들면 2만 개 이상의 바구니를 사용해야 할 것이다. 즉, 속도는 빠르지만, 어느 순간부터 첫 글자인 H에 해당하는 배열에 모든 이름을 넣는 것이 더 나을 때가 온다는 것이다. 그렇게 된다면 그냥 이름표를 찾는데 시간이 좀 더 걸리는 게 낫다.
만약 해시 함수가 이상적이라면, 각 바구니에는 단 하나의 값들만 담기게 될 것이다. 따라서 검색 시간은 O(1)이 된다. 하지만 그렇지 않은 경우, 최악의 상황에는 단 하나의 바구니에 모든 값이 담겨서 O(n)이 될 수도 있다. 일반적으로는 최대한 많은 바구니를 만드는 해시 함수를 사용하기 때문에 거의 O(1)에 가깝다고 볼 수 있다.
2. 트라이(tries)
트라이는 발음은 다르지만, 검색(retrieval)의 줄임말이다. 트라이는 트리 형태로 되어있으며, 어떤 자원을 절약하기 위해서 다른 자원을 소비하는 패턴을 갖는다. 트라이에는 많은 메모리가 사용되지만, 자료구조 안에 있는 이름이나 단어를 찾는 데 일정한 실행시간을 갖는다. 특이한 점은 각 노드가 배열로 이루어진 트리라는 것이다.
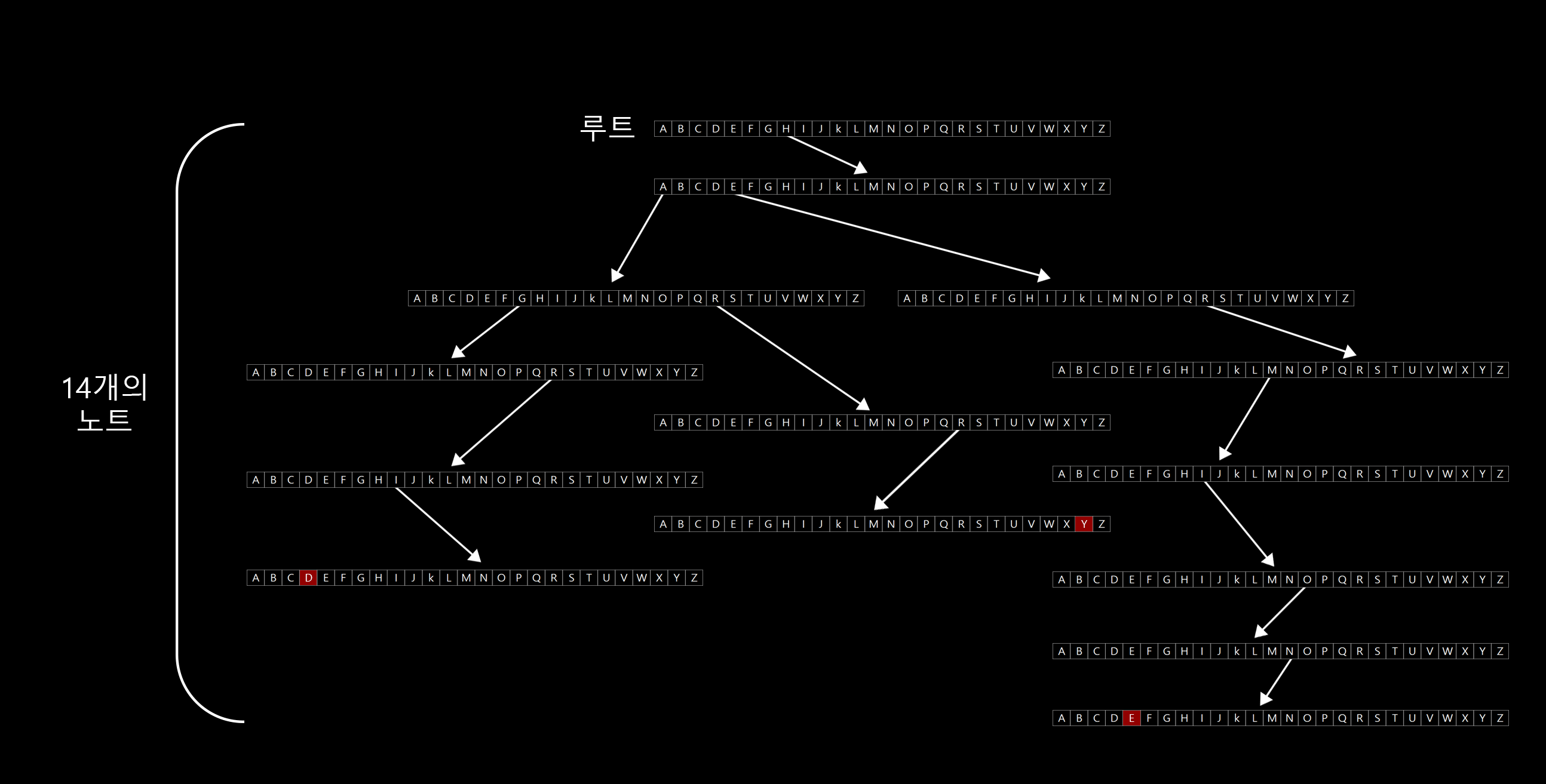
컴퓨터 공학자들은 영리하게도 이 아이디어, 저 아이디를 가지고 융합해서 괴물 같은 자료구조를 듦과도 동시에 시간과 메모리를 아낄 수 있게 되었다. 트라이는 각 노드가 배열로 구성되어있는 트리이며, 맨 위에 있는 배열은 트라이의 루트를 뜻한다. 14개의 배열크기는 A부터 Z까지 혹은 0부터 25까지 26칸이다. 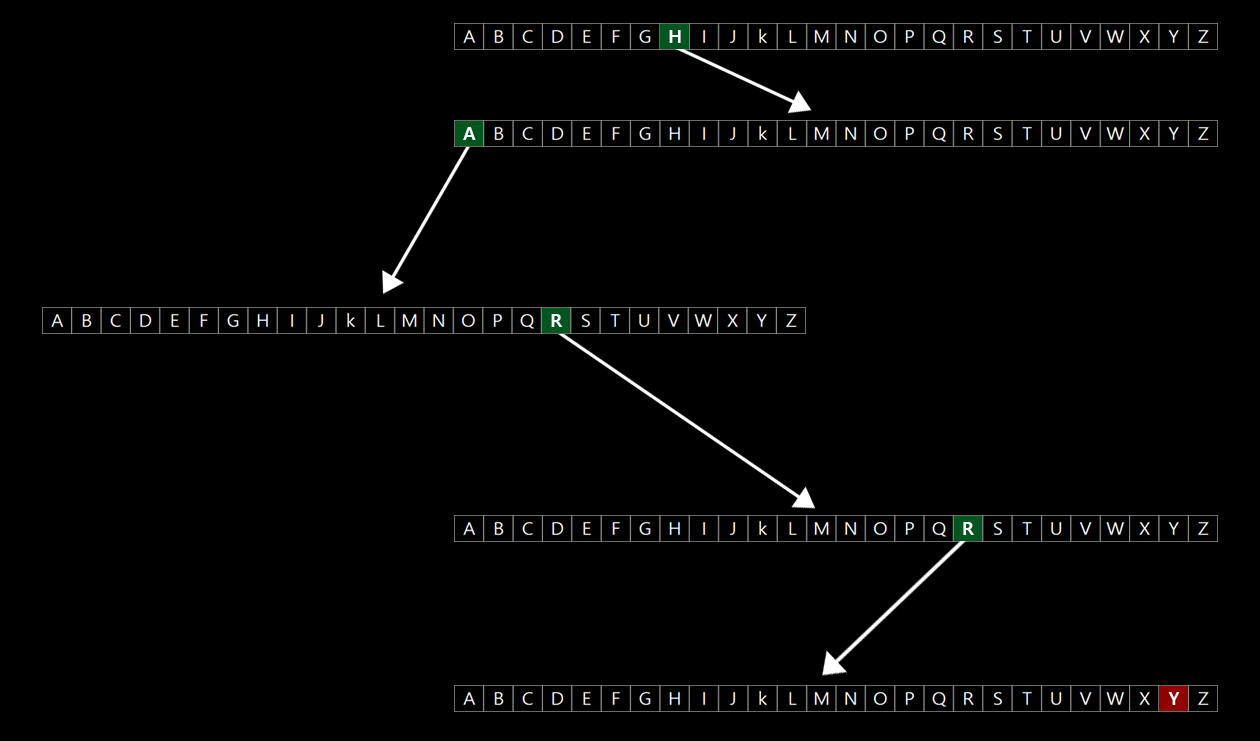
만약 트라이에 이름을 저장하고 싶은 경우 이름의 모든 글자를 봐야 한다. Harry의 경우에는 H a r r y 가 될 것이다. 해시테이블처럼 첫 번째, 두 번째, 세 번째 글자만 보는 것이 아니라 모든 글자를 봐야 한다. Harry의 첫 글자는 H이기 때문에 해당하는 인덱스로 간다. 만약 거기에 자식노드가 없으면 그 아래에 다른 트리, 혹은 가지가 없으면 새로운 노드를 할당한다. (여기서 새로운 노드란, 다시 말해서 새로운 배열이 되겠다) 그런 다음에 같은 방법으로 a에 해당하는 인덱스로 가서 자식노드가 없으면 그 아래에 다른 트리, 혹은 가지가 없으면 새로운 노드를 할당한다.
마지막 글자까지 표시하면 끝이 난다. 마지막 글자인 Y에는 붉게 표기했다. C언어에서는 블리언 연산식으로 이름 하나가 끝났다는 것을 표기할 수 있다. 이제 이 이름의 각 글자에 대해서 하나의 노드 혹은 배열을 저장하면서 Harry라는 이름을 묵시적으로 저장할 수 있게 된다.
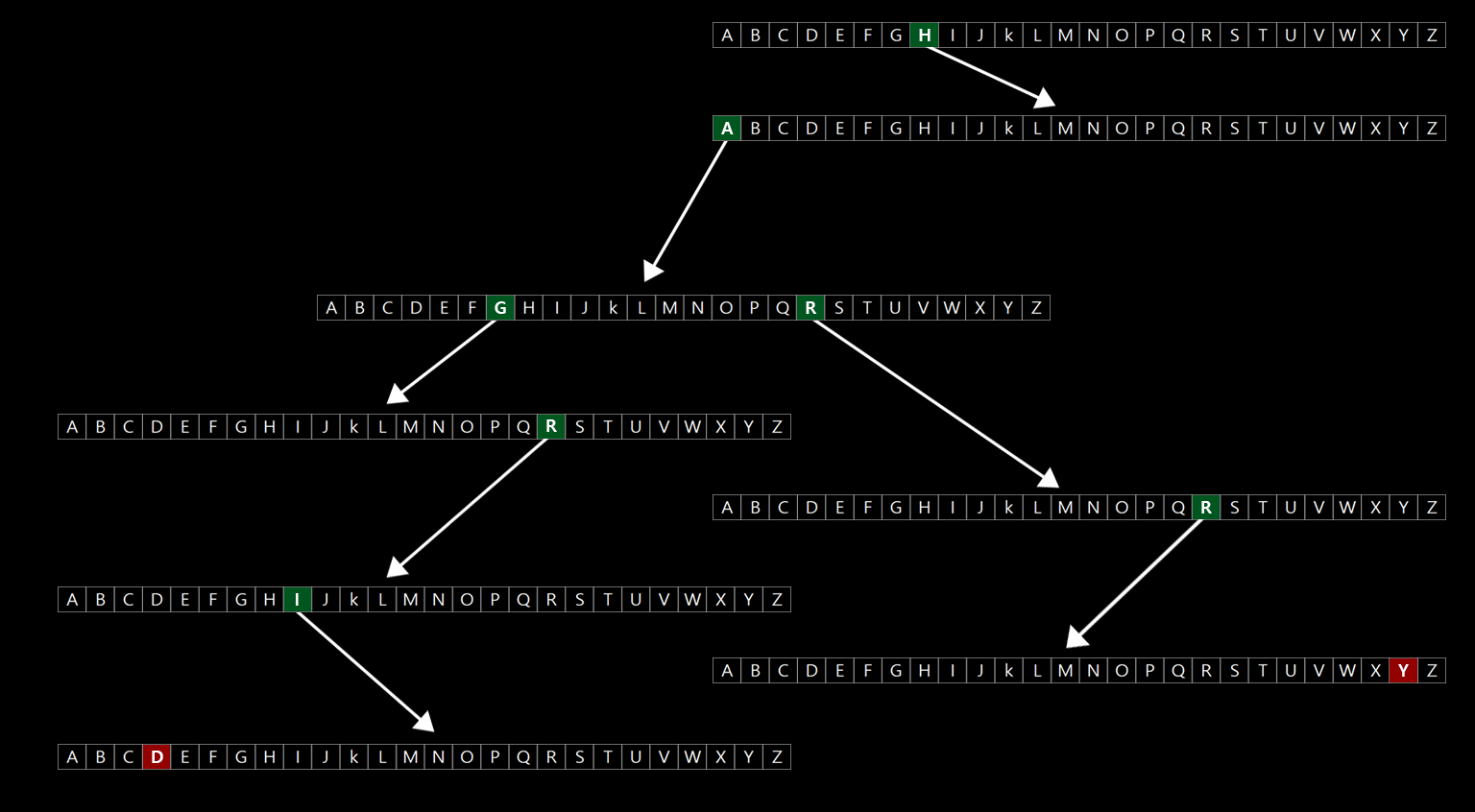
그러나 여기에 Harry의 접두사나 같은 접두사를 가진 다른 이름들이 저장되기 때문에 어느 정도 효율성이 있다고 볼 수 있다. 예를 들어 이 자료구조에 Hagrid라는 이름을 넣고 싶다고 하자. H a g r i d 를 넣기 위해 3개의 노트가 더 생겼다.
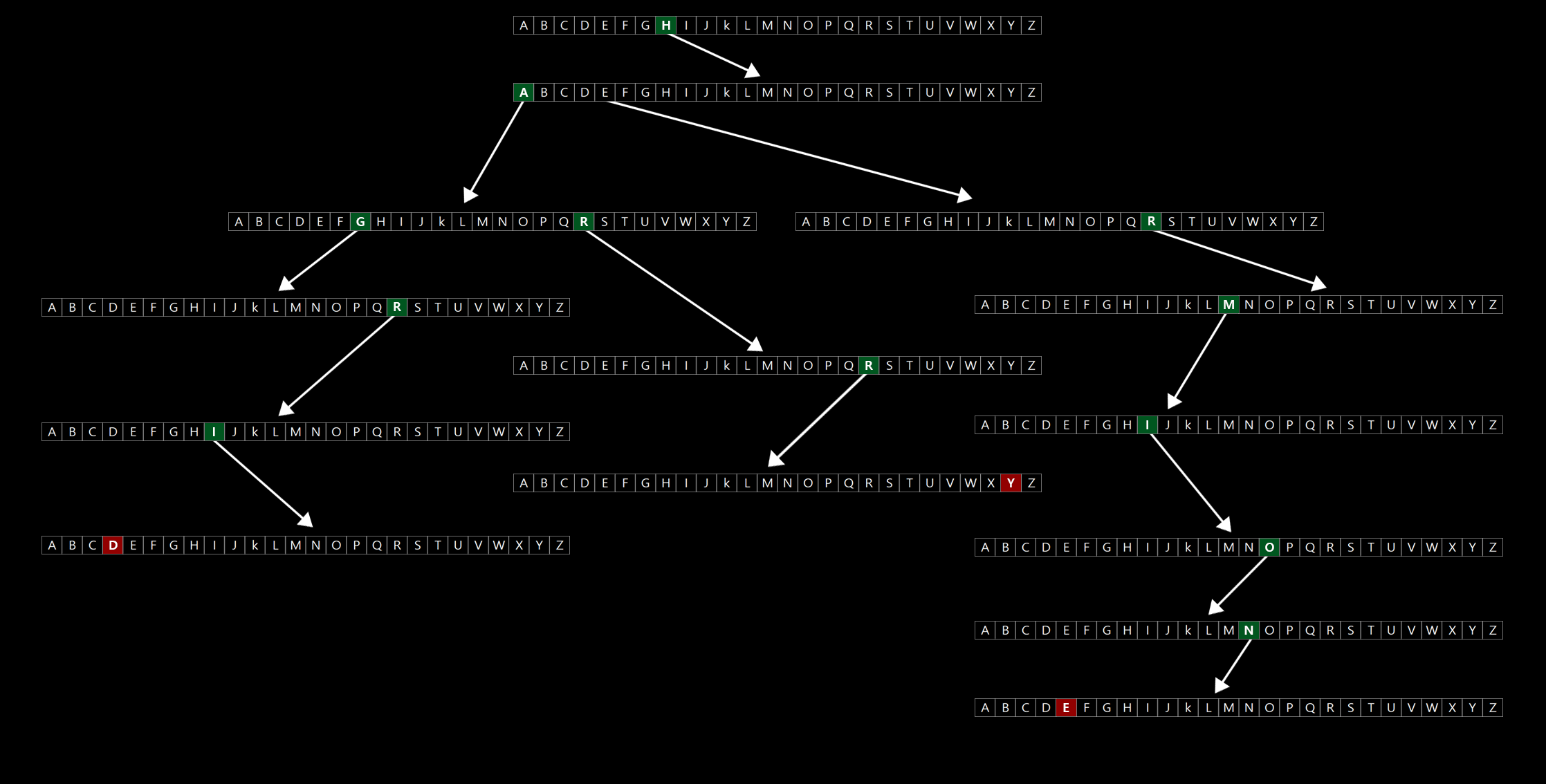
이어서 Hermionie를 넣고 싶으면 왼쪽에 6개의 노드가 더 생기는 것을 알 수 있다. 전체 그림을 보고 있노라면 몇몇 노드는 공유한다는 것을 알 수 있다. 맨 위에서 시작해서 H를 바라본다면 Harry와 Hagrid, Hermioine 모두가 최소 하나의 노드를 나누어 가진다는 것을 알 수 있다.
그렇다면 궁극적으로 이것이 멋진 이유는 무엇일까. 누군가의 이름을 찾기 위한 실행시간이 O(1)이기 때문이다. Harry가 자신의 이름표를 찾기 위해서 거쳐야 하는 단계 수는 5이다. Hagrid는 6, Hermione는 8단계를 거쳐야 한다. 그리고 가장 긴 이름이 있다고 해도 그 개수가 20개이면 20단계, 30개이면 30단계일 것이다.
하지만 사람의 이름은 시간이 지날수록 길어지는 것이 아니다. 즉, 고정된 상한값이 있다는 말이다. 고정값이 있을 때 수학적으로 혹은 컴퓨터 공학적으로 이것을 상수라고 부른다. 그래서 트라이라는 자료구조를 탐색하거나 삽입할 때, k 값이 상수인 O(k)라는 실행시간을 달성할 수 있는 것이다. 정리하자면 O(k)는 O(1)과 같기 때문에 트라이의 실행시간은 이름을 찾기 위해서 걸리는 시간은 O(1)이 된다. (트라이에 1000만 개의 다른 이름이 있고, 다수의 책 안에 Harry라는 이름이 들어있어도 상관없다. 왜냐하면 Harry를 찾기 위해서는 H a r r y가 속해있는 노드들만 보기 때문이다.)
정렬 알고리즘, 연결리스트, 이진탐색트리 등을 떠올리면 트라이라는 알고리즘은 자료구조에 있는 이름의 개수에 따라 실행시간이 길어졌지만 트라이는 그렇지 않다는 점에서 매우 유용하다는 것을 알 수 있다..
하지만 시간복잡도 좋은 만큼 공간복잡도는 다소 기능이 떨어질 수 있다. 위 그림에서도 한 글자의 이름을 저장하기 위해 26개의 메모리(26배이다.)를 사용한다는 것을 볼 수 있다.
지금까지 배열과 연결리스트, 트리, 트라이 그리고 해시테이블을 배웠고, 그 외에도 다양한 자료 구조가 있었다. 이러한 것들을 이용해서 추상 자료형이라는 것을 구현할 수 있으며, 그들의 요소를 가지고 다른 문제를 해결하는 데에도 사용할 수 있다.
3. 큐

큐는 줄서기로 이해하면 좋다. 가게나 식당 앞에 있는 대기 줄처럼 먼저 들어온 데이터가 먼저 나가는 방식을 따른다. 이것을 선입선출(FIFO)이라고 부른다. 사실 정의에 따르면 큐는 사람들이 앞으로 줄을 선 것이고, 선입선출이 유지되도록 하는 것이다. 이는 가게나 식당뿐만 아니라, 요청한 순서대로 프린트되는 공용 프린터기에서도 마찬가지이다.
실생활에서 사용하지는 않지만, 큐에서는 두 가지 기본 연산이 있다. enqueu와 dequeue이다. enqueu는 줄에 들어가서 서는 것이고, dequeue는 줄에서 빠져나오는 것이다.
배열이나 연결 리스트로 큐의 개념을 구현할 수 있다. 가게에서 사용하는 소프트웨어에서는 큐를 구현하기 위해서 동적으로 크기가 바뀌는 배열이나 더 좋은 방법으로는 연결리스트를 이용해서 사람들이 늘어나고 줄어들고 하는 등의 주문을 받고 처리하는 상황을 구현할 것이다.
4. 스택
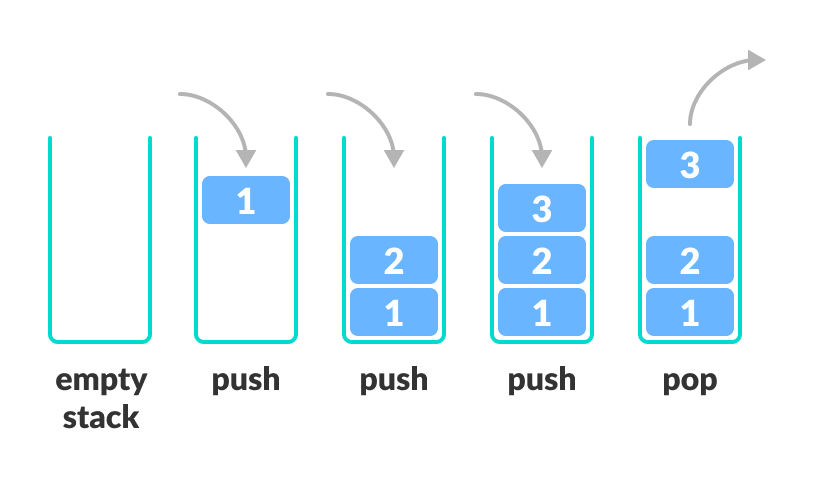
반면 스택은 역시 메모리 구조에서 살펴봤듯이 값이 위로 쌓이는 구조이다. 현실에서는 아래부터 쌓이지만, 위에서부터 꺼내기는 학생 식당의 식판에 대입하면 된다. 따라서 스택은 값을 넣고 뺄 때 ‘후입 선출’ 또는 ‘LIFO’라는 방식을 따르게 된다. 가장 나중에 들어온 값이 가장 먼저 나가는 것이다.
또 다른 예시로는 메일함을 볼 수 있다. 특히 Gmail을 받는 메일함은 기본적으로 스택으로 설정되어있다. 가장 최근에 받은 메일이 가장 위에 위치하기 때문이다. 여기서도 트레이드오프는 존재한다. 스택을 이용했을 때, 최신메일을 받아볼 수 있지만, 메일이 많이 오는 사람은 금방 2페이지로 넘어가서 메일을 못 보게 될 수도 있다.
스택에도 두 가지 기본 연산이 있는데 enqueu와 dequeue 대신에 관례로 push와 pop이라고 부른다. 스택에 어떤 요소를 밀어 넣는다는 뜻으로 push라고 부르고 가장 위 요소를 뺀다는 의미로 pop이라고 부른다.
역시 배열이나 연결 리스트를 통해 구현할 수 있다.
5. 딕셔너리
컴퓨터 공학에서 딕셔너리는 키와 값, 단어와 값, 단어와 페이지 번호 그리고 그 외의 다양한 쌍으로 이루어진 자료구조를 말한다. 해시 테이블이라고도 생각할 수 있다. 해시 테이블에서는 바구니를 사용했고 코드에서는 배열과 연결리스트를 사용했다. 역시 ‘키’를 어떻게 정의할 것인지가 중요하다.
